
The Buckeye Speech Corpus
The Buckeye Corpus of conversational speech contains high-quality recordings from 40 speakers in Columbus OH conversing freely with an interviewer. The speech has been orthographically transcribed and phonetically labeled. The audio and text files, together with time-aligned phonetic labels, are stored in a format for use with speech analysis software (Xwaves and Wavesurfer).
This project is funded by the National Institute on Deafness and other Communication Disorders and the Office of Research at Ohio State University.
The corpus is FREE for noncommercial uses
1) Go here to register to obtain a copy of the corpus.
2) Learn about the corpus here.
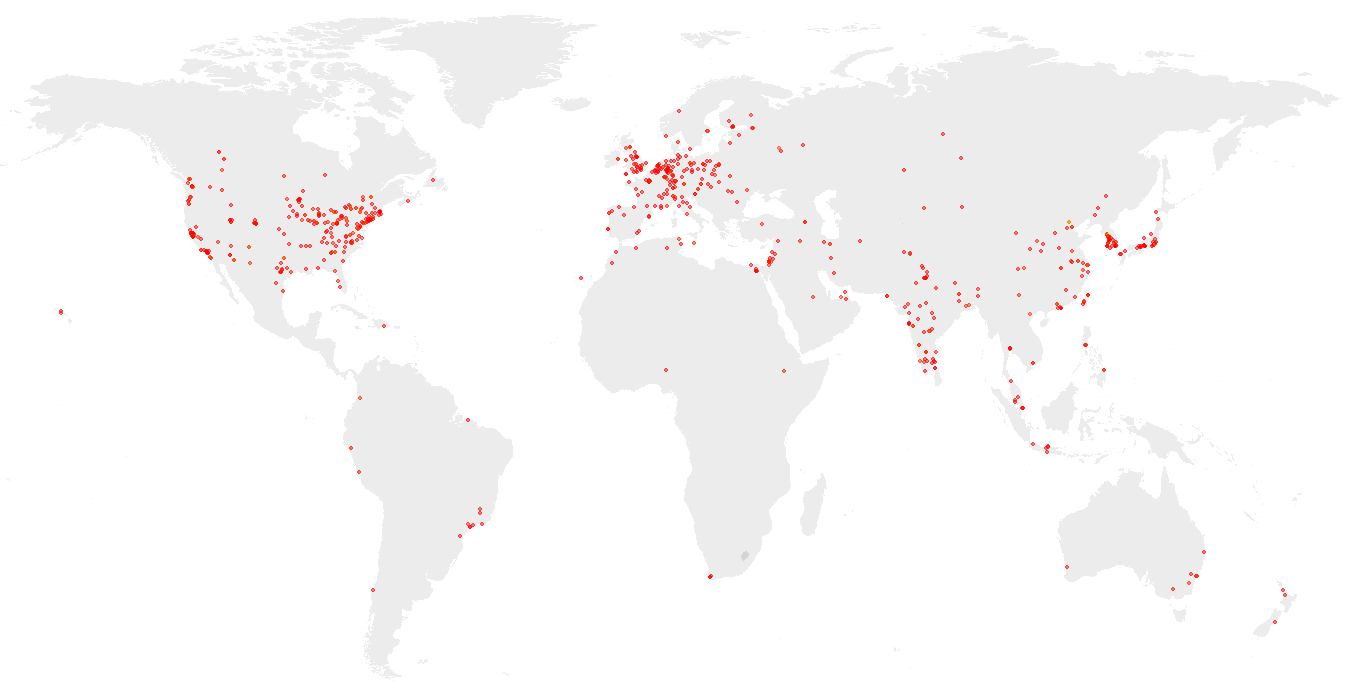
Locations of users
Saloni Mathur, Makaylah Ekegren, Maya Regule, Mohamad Bamdad, Delilah Rodriguez, Rachel Grobman